A few years ago, I was hooked on the idea of Domain-Driven-Design (DDD) and microservices architecture and what is the best way to learn than building an application. So, I decided to build a human resource application but at the same time how to cut starting costs without compromising application (performance, security…) if to start a SaaS company and grow overtime.
For the first part, I have no experience of DDD and bounded context. So, this required a lot of reading and going back and forth on how to break my solution into domains and if my breaking was correct or not – this still an ongoing question.
The second part, how to cut start and operation costs for the solution and the SaaS company. For this part, I had to evaluate many solutions and technologies before I started and while working on the application. For example,
- Jira + Confluence vs Youtrack
- Database: MS Server vs PostgreSQL
- Docker image Registry: Docker Hub vs AWS ECR
During this journey I was researching, experimenting and refactoring a lot since I was working on this project by myself and there is no time constraint. Someone might ask, why didn’t you plan everything at the start? The answer, it is the same as any new software. You plan for whatever details you have while trying to predict and plan for the future, but it is hard if not impossible, like when you decide on a certain tool but after sometime and with new requirements you find out that it does not answer them so you start looking for alternatives.
I’m happy where I’m right now in both architecture and implementation decisions, so I decided to write about it. Now, this could change as I consider billing and subscription or other parts like payroll.
One thing for sure, where I’m right now is just a start and not the end.
Challenges:
On top of my head these are the challenges I ran into since the start.
- No experience in DDD and bounded context.
- How to avoid chatty microservices
- First implementation, the system was too chatty, many events between microservices which made it hard to track.
- How to organize and structure the solution and the UI application.
- How to abstract and avoid any duplicated code.
Architecture:

Rules I followed while working on the system:
- Accessing the domain only through the gateway
- No database models can be used outside the domain
- You shouldn’t pass more information to the user than they need.
- Trying to mitigate exposing sensitive information to the normal user.
- Communication between domains is either through the gateway OR through events
- Single database but a microserivce(s) per table.
- The infrastructure layer is used as a shared layer between domains for specific use cases like storing event tracking.
- Each domain is built internally as layer architecture .
- Abstraction for everything when possible (Both backend and frontend).
- This simplifies changing libraries when needed.
- Like changing logging library from Serilog to something else or changing message broker from RabbitMq to AWS SQS.
- Changing UI framework (Ex:- Quasar) to something else.
- Hide implementations.
- Your solution does not need to know what library used for logging or serializer. It only needs to know what are the inputs and the outputs.
- Your exception does not need to know about (x) types of exceptions the library throws.
- This simplifies changing libraries when needed.
- If a microservice needs details from another microservice (table), then fetch these details in the gateway and pass it with the event.
- Here, you will need to check the message broker and its limitation in term of max message size.
CI/CD and testing
Test-Driven-Development TDD was followed during implementation, not for everything. Few things are more suited for other types of testing. When trying new libraries, I start a new solution and build the code there then copy it back to the main solution. In this case, part of the code is already written so it is hard to say it followed TDD.
AWS CodePipeline and AWS CodeBuild are used for performing unit tests, build and push docker images to AWS ECR. However, I’m not sure if it will be configurable to automate other types of tests, such as:
- Integration tests
- Penetration tests
- e2e tests
- Synthetic tests
Challenges (Maybe a rant):
Some of the challenges I ran into other than DDD are
- Google search results:
- I can categories google search into 2 categories:
- Category 1 (Redundant content). Many of the blogs re-write the same content without any enhancement, I even saw some blogs copied a whole content from Microsoft without any changes.
- Category 2 (Unrelated results): Sometimes Google return unrelated results, but I have to admit sometimes it is due the searched words used but other times it feels their algorithm went haywire.
- I can categories google search into 2 categories:
- People answers.
- Some of the answers just echo an answer they read somewhere. An example, when selecting SQL VS NoSQL Database. Everyone answer was if you can be a table then SQL database, but is that simple? It leaves out many of the application dependent questions, like:
- Is the application Read heavy?
- At any point of time, can records be different?
- Is it a key-value like queries? or what type of queries you will perform against the database?
- People comment for sake of comment (LOL).
- Some of the answers just echo an answer they read somewhere. An example, when selecting SQL VS NoSQL Database. Everyone answer was if you can be a table then SQL database, but is that simple? It leaves out many of the application dependent questions, like:
- Not many production experiences shared on the internet.
Miscellaneous statistics:
- Total .Net projects in the solution: 153 + 1 (UI)
- 36 Microservice/Container
- 62 Test project and test utilities/helpers
- 819 unit tests
- 49% test coverage (Rider coverage test)
- 55 Libraries, Events, Models, …
- Total commits (Master/Main branch): 610
- Over 90% of the commits are squashed commits
- Line of code (.cs files – C#): Around 13,500
Technologies and libraries:
- Frontend: Vue3, Pinia, Quasar, AWS Amplify/ui-vue, vue-i18n
- Backend: .Net 9, Masstransit, Serilog, Newtonsoft, Npgsql EF Core, AutoMapper
- Masstransit: Opensource distributed application framework, provides tons of abstractions like with AWS SQS, RabbitMq, Azure, and more. They have commercial support.
- Npgsql EF Core: EF Core for PostgreSQL database
- Testing: MSTest, Moq
- Tools: Jetbrain (Youtrack, Rider), Docker Desktop, MS Visio
- Youtrack: Like Jira and Confluence and used for Issue tracking but provide help desk feature. It was used to manage tasks/stories to work on.
- CI/CD: AWS ECR (Container registry), AWS CodeBuild, AWS CodePipeline
- Containerization: Docker, Docker compose
- Databases/Storage: PostgreSQL, Valkey (Fork from Redis), AWS S3
- Message broker: RabbitMq
- Git repository: Bitbucket
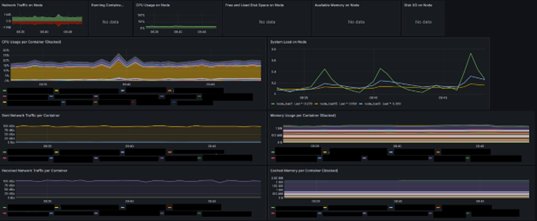
- Monitoring and logging: AWS CloudWatch, Grafana (Loki, Prometheus, CAdvisor, Grafana, Promtail)
- Allows to visualize containers and system usage (CPU, Memory, Network)
What is next?
Some of the things I will work are:
- Perform load test and
- Update containers resources configuration (CPU/Memory) AND/OR
- Introduce load-balancers (Gateways, DataAccess), replicate containers (Services listen to message broker)
- Re-evaluate CI/CD for automating missing tests (Integration,…)
- Rebuild Youtrack backlog and continue working on other part of the application.